An Intelligent Assistant for Software Publication
The OntoSoft project is developing an on-line community portal for sharing knowledge about geosciences software. In the initial stages of the project, we are developing a portal that will provide:
- Intelligent assistance to describe software: how to use it appropriately, what kinds of data, how it relates to other software, and other important metadata that helps promote reuse
- Sophisticated search capabilities to find software for specific needs
- Interactive advice on software sharing, including open source publication, forming successful developer communities, and other software sharing topics
A detailed description can be found in this paper:
- OntoSoft: Capturing Scientific Software Metadata. Gil, Y.; Ratnakar, V.; and Garijo, D. In Proceedings of the Eighth ACM International Conference on Knowledge Capture, Palisades, NY, 2015.
The source code for OntoSoft can be found on github:
Accessing the OntoSoft Portals
OntoSoft portals are set up for particular communities and institutions, and are integrated into a general portal. In our current work, we are creating a single entry point so users can easily search across portals.
Click here to access the portals
Using the OntoSoft Portal
Describing software:
Searching for software: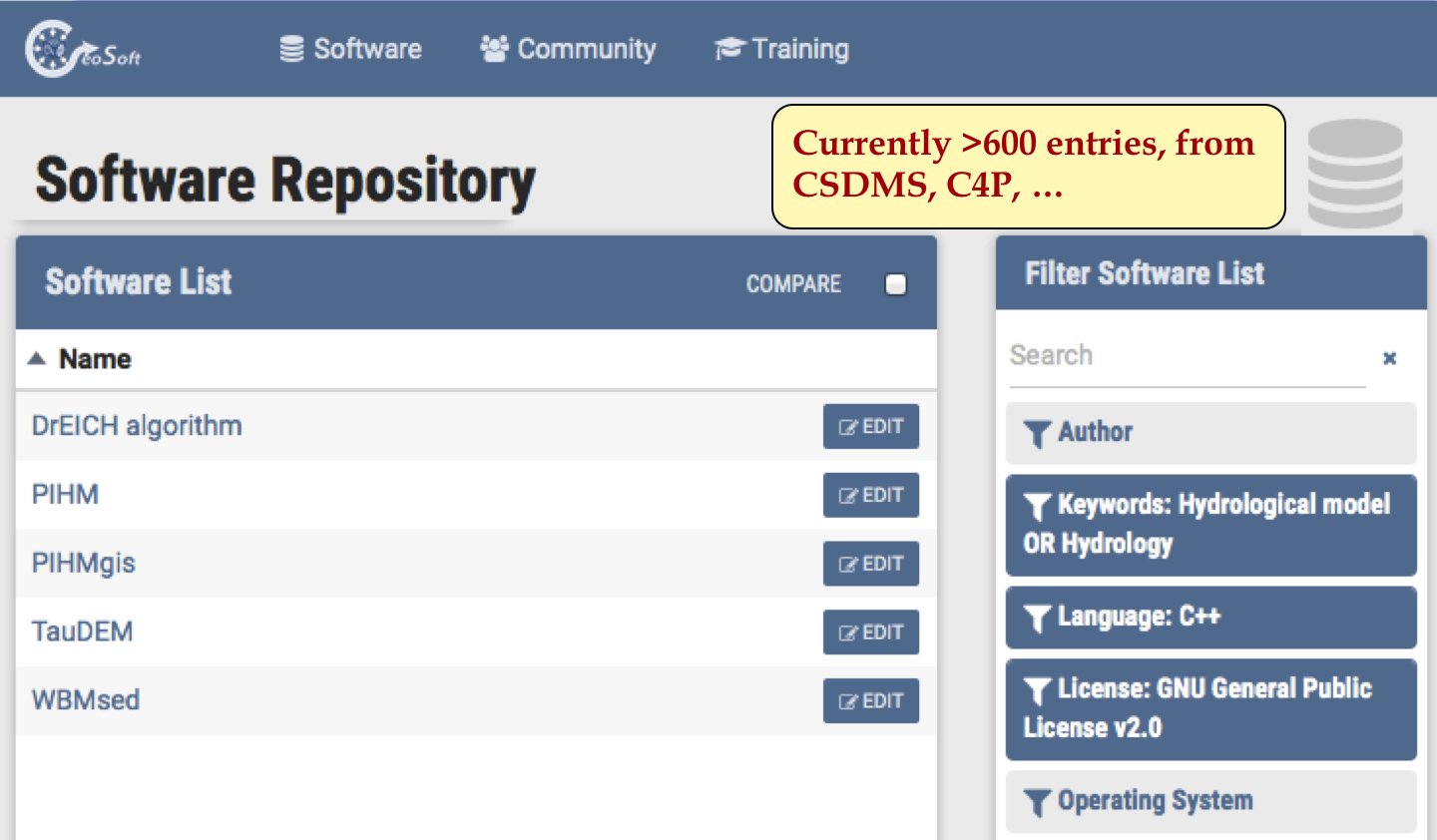
Comparing software: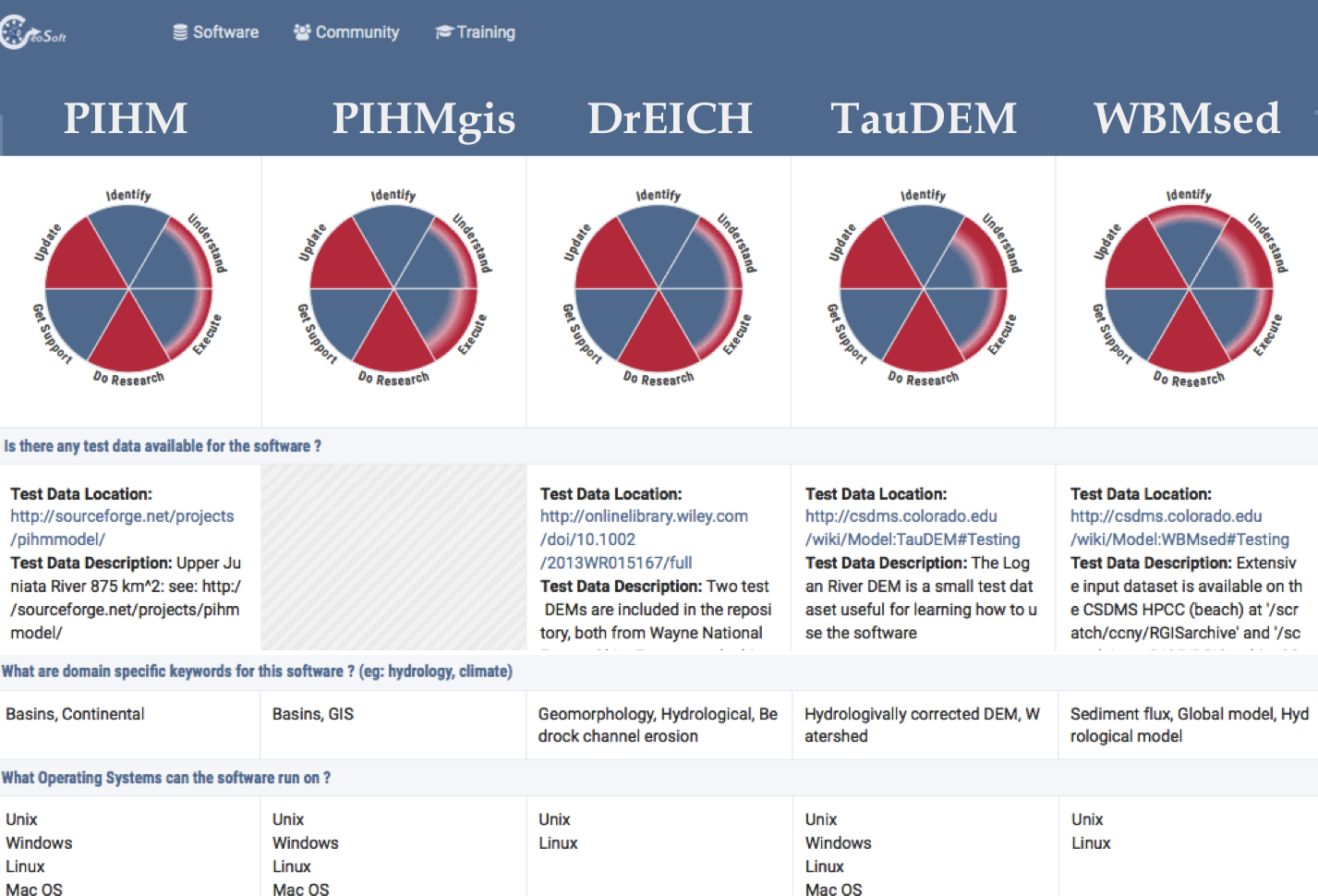
History
The first version of OntoSoft was released in 2014, and was called TurboSoft. We evaluated TurboSoft with scientists in terms of usability and metadata quality. We learned a lot from these evaluations, which led to a redesign of our approach and ultilately to today's OntoSoft. You can explore the TurboSoft portal by logging in as “guest”. The source code of TurboSoft is available open source on GitHub under an ALv2 license.
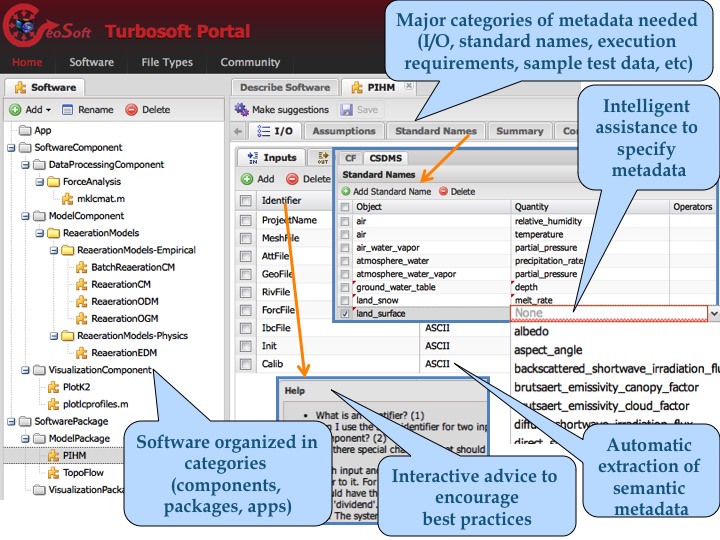
TurboSoft already interfaces with current model repositories such as Community Surface Dynamics Modeling System (CSDMS), and soon Computational Infrastructure for Geodynamics (CIG) and others.
TurboSoft Demonstration videos
Our focus to date has been TurboSoft, an intelligent assistant that guides users through best practices for publishing their software. Here are a few demonstrations of the initial TurboSoft prototype. We continue to extend TurboSoft and welcome your suggestions.
TurboSoft Prototype Demonstration: Advice on Best Practices
TurboSoft provides interactive advice to encourage best practices in preparing code for software sharing. In this demo, TurboSoft does a simple analysis of the code and looks for potential problems and offers suggestions to fix them. In the example shown, when there is OS-specific code or hardcoded paths TurboSoft suggests that they be replaced with more general code. These checks are based on best practices for open software sharing and reuse.
TurboSoft Prototype Demonstration: Automatic Metadata Extraction
TurboSoft automatically extracts metadata to describe software, so the user does not have to provide it by hand. In this demo, TurboSoft takes examples or test datasets, and extracts the MIME types of data as metadata of the inputs and outputs of the software. The extracted metadata allows TurboSoft to suggest visualizations or other software that can be used for those data types. The metadata extraction is done using Apache Tika.
TurboSoft Prototype Demonstration: Automatic Metadata Inference
TurboSoft automatically infers new metadata to describe software, so the user does not have to provide it by hand. In this demo, when a user specifies standard names or assumptions for their model, TurboSoft infers other assumptions made by the model. The inferences are based on rules based on semantic representations of standard names and assumptions represented using Semantic Web standards.
TurboSoft Prototype Demonstration: Scalable Search
TurboSoft supports scalable search through the software repository. In this demo, the user searches for specific kinds of software, such as software that outputs a certain type of data or software that is open source. This faceted search is done using Apache Solr.